
Produk suara real-time hidup atau mati karena latensi. Baik itu asisten suara, penyiar dalam game, atau alat terjemahan langsung, seberapa cepat ucapan mulai diputar menentukan keseluruhan pengalaman pengguna. Bagi pengembang, milidetik itu penting. Semakin cepat model mulai memproduksi audio, interaksi akan terasa semakin “hidup”.
Dalam benchmark ini, kami mengevaluasi yang tercepat streaming TTS model dari API Suara Asinkron, SebelasLabsDan Kartesius untuk lebih memahami keseimbangan antara latensi dan kualitas suara yang dirasakan. Secara khusus, kami mengukur dan membandingkan:
• Latensi tingkat model – waktu yang dihabiskan hanya untuk inferensi GPU, tidak termasuk overhead jaringan dan aplikasi.
• Latensi ujung ke ujung – waktu dari inisiasi permintaan hingga byte audio pertama (TTFB) yang diterima oleh klien.
• Kualitas audio subyektif – dinilai menggunakan berpasangan Peringkat Elo di beberapa sampel suara.
Semua tolok ukur dieksekusi dalam kondisi yang sama, diulangi beberapa kali untuk keyakinan statistik, dan dirata-ratakan di seluruh kumpulan cepat yang diacak untuk menghindari bias caching.
Metodologi
Untuk mengukur performa streaming dunia nyata secara akurat, kami menggunakan kerangka kerja benchmarking dua lapis yang dirancang untuk memisahkan kecepatan model mentah dari latensi end-to-end penuh. Hal ini memungkinkan kami untuk mengisolasi seberapa besar penundaan yang berasal dari inferensi model itu sendiri versus overhead infrastruktur atau jaringan, yang merupakan perbedaan utama bagi pengembang yang mengoptimalkan sistem real-time.
Dengan mengukur kedua lapisan tersebut, kami mendapatkan gambaran lengkap tentang kinerja sistem, mulai dari efisiensi infrastruktur hingga respons yang dirasakan pengguna. Metodologi ini sangat relevan untuk kasus penggunaan streaming berlatensi rendah seperti asisten suara AI, dubbing real-time, narasi langsung, dan pemutaran transkripsi, yang bahkan penundaan 100 mdtk dapat membuat interaksi terasa lamban atau tidak sinkron.
Lingkungan pengujian
Kami menjaga agar setiap benchmark tetap dijalankan pada klien dan pengaturan jaringan yang sama agar perbandingannya adil dan dapat diulang. Dengan begitu, perbedaan apa pun yang Anda lihat berasal dari model itu sendiri, bukan dari gangguan jaringan atau kekhasan perangkat keras.

Semua evaluasi dilakukan dengan menggunakan streaming titik akhir APIjika tersedia, untuk diukur latensi byte pertama Dan throughput audio terus menerus.
Untuk menghilangkan bias pemanasan, setiap model menjalaninya tiga kali pemanasandiikuti oleh 20 iterasi terukurdengan metrik yang dikumpulkan menggunakan nilai median dan p95 (persentil ke-95).
Latensi inferensi model
Sebelum memperhitungkan overhead API atau jaringan, latensi inferensi model mencerminkan kecepatan komputasi mentah model text-to-speech yang berjalan pada perangkat keras GPU. Metrik ini mengisolasi seberapa efisien model itu sendiri mengubah teks menjadi bingkai audio, terlepas dari protokol streaming atau konektivitas klien.
Latensi inferensi yang lebih rendah biasanya menunjukkan:
• Optimalisasi arsitektur yang lebih baik
• Waktu respons lebih cepat pada perangkat keras GPU yang setara
• Mengurangi biaya penyajian ketika diterapkan dalam skala besar
Tabel berikut merangkum performa inferensi murni untuk model streaming andalan masing-masing penyedia.

Catatan: Arsitektur AsyncFlow dioptimalkan untuk GPU L4mencapai waktu inferensi mendekati tingkat dasar ~20 mdtk. Kurangnya informasi GPU yang diungkapkan dari ElevenLabs dan Cartesia menunjukkan bahwa hasil mereka mungkin bergantung pada GPU tingkat yang lebih tinggi, yang membuat rasio efisiensi terhadap biaya AsyncFlow semakin menonjol.
Tolok ukur latensi streaming (end-to-end)
Meskipun kecepatan inferensi mentah menunjukkan seberapa cepat suatu model dapat memproses teks pada GPU, latensi streaming end-to-end menentukan seberapa responsif model tersebut dalam aplikasi nyata. Untuk mencatat penundaan startup dan total waktu penyelesaian, kami mengukur Time to First Byte (TTFB) dan total durasi audio di beberapa proses.
Setiap tes terdiri dari:
• 20 iterasi benchmark per model (setelah tiga kali pemanasan dijalankan untuk menormalkan efek cold-start)
• Kondisi klien yang konsisten dari us-central1
• Permintaan streaming HTTPS menggunakan perintah teks dan konfigurasi audio yang identik
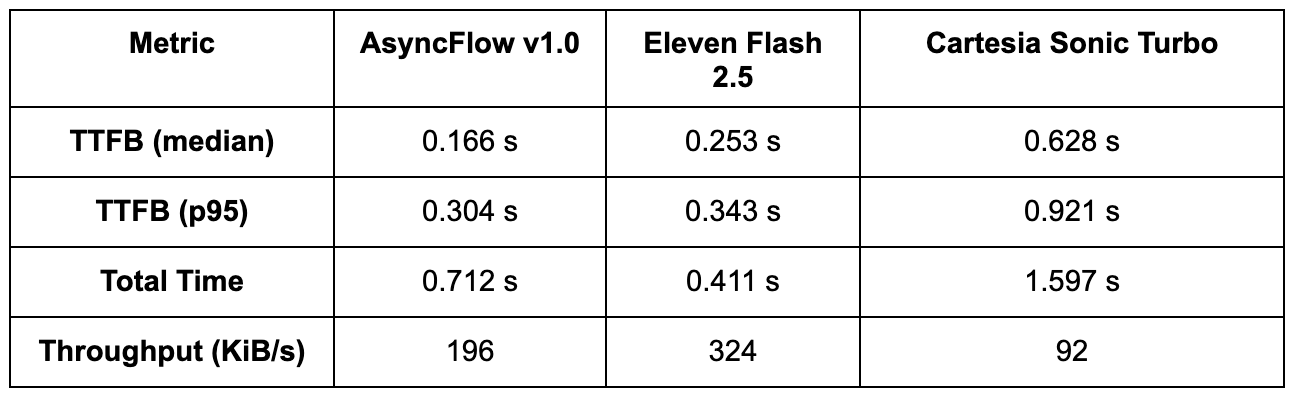
Catatan: p95 (persentil ke-95) menunjukkan bahwa 95% permintaan diselesaikan lebih cepat dari waktu ini, sehingga memberikan ukuran konsistensi latensi yang realistis saat dimuat.
Interpretasi:
• AsyncFlow mengirimkan audio paling awal; median TTFB di bawah 200 ms membuatnya ideal untuk aplikasi interaktif atau percakapan di mana pengguna mengharapkan ucapan dimulai hampir seketika.
• Sebelas Flash melakukan streaming pada latensi yang sedikit lebih tinggi namun mencapai penyelesaian total lebih cepat, menunjukkan strategi buffering atau chunking yang lebih agresif.
• Cartesia Sonic Turbo tertinggal jauh di belakang keduanya, dengan TTFB lebih dari 3× lebih lambat dan throughput lebih rendah, yang mungkin membatasi kesesuaiannya untuk kasus penggunaan real-time.
Pengukuran ini mencakup model, tumpukan API, dan latensi jaringan, yang memberikan cerminan nyata dari kinerja streaming yang dirasakan klien.
Contoh kode pembandingan
Agar pengukuran kami tetap transparan dan dapat direproduksi, kami menggunakan skrip pembandingan Python sederhana yang mencatat waktu-ke-byte pertama (TTFB) dan total durasi respons untuk setiap API streaming penyedia. Skrip mengirimkan perintah teks yang identik, memberi stempel waktu pada peristiwa penting (permintaan dimulai, potongan audio pertama, dan byte terakhir), dan menggabungkan hasilnya di beberapa proses untuk menghitung latensi median dan p95.
👉 Kode pembandingan latensi Di Sini.
Anda dapat dengan mudah mengadaptasi skrip ini untuk menguji model atau infrastruktur Anda sendiri dengan menyesuaikan URL titik akhir, format muatan, atau parameter konkurensi.
Evaluasi kualitas subjektif
Ini adalah evaluasi internal yang mengikuti kerangka TTS Arena, dengan fokus hanya pada tiga model latensi rendah. Di TTS Arena publik, model sering kali menargetkan kasus penggunaan yang berbeda, sehingga sulit untuk membandingkan kualitas model latensi rendah secara langsung.
Panel yang terdiri dari 20+ peserta mengevaluasi ~500 perbandingan berpasangan, setiap kali memilih sampel yang terdengar lebih alami, ekspresif, dan bebas artefak. Hasilnya dikumpulkan dan dinormalisasi menjadi skor Elo, yang mengukur kekuatan preferensi relatif, bukan kualitas absolut.

Temuan:
• Eleven Flash v2.5 mencapai skor Elo tertinggi, menunjukkan kontrol prosodi yang sedikit lebih kuat dan kejelasan ekspresif, terutama untuk petunjuk yang emosional atau banyak tanda baca.
• AsyncFlow berada di peringkat kedua, dengan kinerjanya yang tetap sangat konsisten dan artefak robotik yang minimal bahkan dalam latensi streaming yang agresif. Mengingat TTFB ~34% lebih cepat dan biaya penyajian lebih rendah, AsyncFlow menawarkan rasio kualitas terhadap latensi yang sangat baik.
• Cartesia Sonic Turbo tertinggal di belakang, dengan preferensi pendengar yang lebih rendah terutama karena artefak sintetik dan penyimpangan intonasi pada kecepatan streaming yang lebih tinggi.
Wawasan gabungan
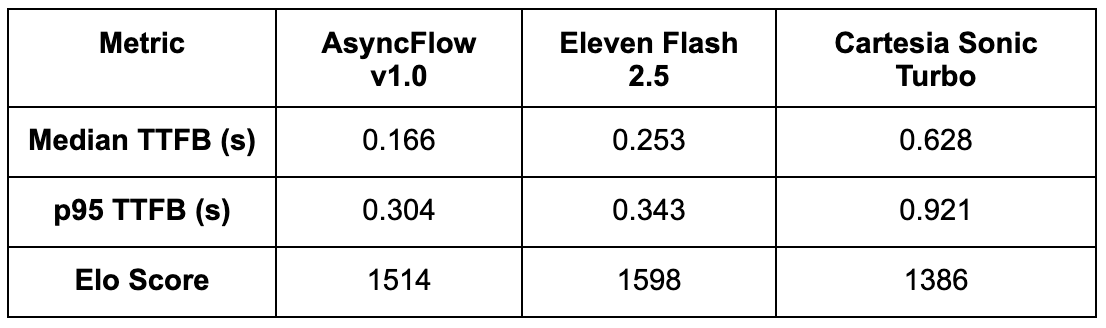
Poin Penting:
• AsyncFlow memimpin secara meyakinkan dalam time-to-first-byte (TTFB), mengungguli ElevenLabs sebesar ~34% dan Cartesia sebesar ~74% dalam latensi median. Pengguna mendengar suara pertama lebih cepat, yang penting untuk pengalaman percakapan secara real-time.
• Bahkan pada persentil ke-95 (p95), AsyncFlow tetap 11% lebih cepat dibandingkan ElevenLabs dan 67% lebih cepat dibandingkan Cartesia, menunjukkan stabilitas dan prediktabilitas di seluruh permintaan, sebuah properti penting untuk aplikasi konkurensi tinggi.
• ElevenLabs mempertahankan sedikit keunggulan dalam kealamian subjektif, khususnya dalam penyampaian ucapan yang ekspresif. Namun, skor Elo AsyncFlow yang mendekati dan latensi yang jauh lebih rendah menjadikannya alternatif yang sangat menarik.
• Arsitektur AsyncFlow menghadirkan latensi terdepan di industri dan efisiensi biaya yang unggul, terutama pada GPU tingkat menengah seperti L4. Untuk pengembang yang membangun pipeline TTS real-time, AsyncFlow menawarkan rasio latensi terhadap kualitas terbaik di antara model yang diuji.
Mengapa latensi di bawah 200 ms penting
Dalam percakapan manusia, bahkan keheningan singkat pun terlihat. Penelitian menunjukkan bahwa manusia mulai merasakan “jeda” sekitar 250–300 ms dalam keheningan. Untuk sistem TTS streaming, mencapai batas di bawah ambang batas ini sangatlah penting: hal ini memungkinkan ucapan terasa lancar, langsung, dan komunikatif, bukan tertunda atau seperti robot.
Mencapai Time-to-First-Byte (TTFB) sub-200 ms memungkinkan berbagai aplikasi real-time:
• Pengambilan giliran alami dalam asisten suara: Pengguna mengharapkan tanggapan instan selama dialog interaktif. Latensi di atas 250 ms dapat membuat asisten suara terasa lamban atau mengganggu.
• Sulih suara latensi rendah untuk streaming langsung: Untuk konten langsung, setiap milidetik berarti. TTS yang lebih cepat memastikan ucapan tetap tersinkronisasi dengan video atau isyarat peristiwa.
• Pemutaran transkripsi waktu nyata: Streaming text-to-speech dapat mengubah keluaran teks menjadi umpan balik yang dapat didengar secara instan, meningkatkan aksesibilitas dan kegunaan untuk teks langsung atau antarmuka berbasis suara.
Dengan TTFB rata-rata 166 ms, AsyncFlow dengan nyaman berada di bawah ambang batas persepsi ini, memberikan respons seperti manusia tanpa bergantung pada perangkat keras GPU tingkat tinggi yang mahal. Hal ini membuatnya sangat cocok untuk aplikasi interaktif dengan latensi rendah dalam skala besar.
Sumber daya & reproduktifitas
• Kode pembandingan latensi
• Dokumen Pengembang Async Voice API
• Cartesia API Reference
• Dokumen API Streaming ElevenLabs
Kesimpulan
AsyncFlow menunjukkan bahwa latensi rendah, kualitas solid, dan efisiensi biaya dapat digabungkan dalam satu mesin TTS streaming.
Meskipun ElevenLabs tetap menjadi tolok ukur dalam kealamian audio, efisiensi arsitektur AsyncFlow, pengoptimalan tingkat GPU, dan TTFB sub-200 ms menjadikannya pilihan menarik bagi pengembang yang membangun sistem suara interaktif dan real-time.
Untuk sistem apa pun yang persepsi daya tanggapnya menentukan pengalaman pengguna, Async Voice API saat ini memimpin di bidangnya.
Langkah selanjutnya
Ingin menjalankan tes ini sendiri? Jelajahi dokumentasi Async Voice API dan coba skrip benchmark dengan masukan Anda sendiri.
News
Berita
News Flash
Blog
Technology
Sports
Sport
Football
Tips
Finance
Berita Terkini
Berita Terbaru
Berita Kekinian
News
Berita Terkini
Olahraga
Pasang Internet Myrepublic
Jasa Import China
Jasa Import Door to Door
Gaming center adalah sebuah tempat atau fasilitas yang menyediakan berbagai perangkat dan layanan untuk bermain video game, baik di PC, konsol, maupun mesin arcade. Gaming center ini bisa dikunjungi oleh siapa saja yang ingin bermain game secara individu atau bersama teman-teman. Beberapa gaming center juga sering digunakan sebagai lokasi turnamen game atau esports.

